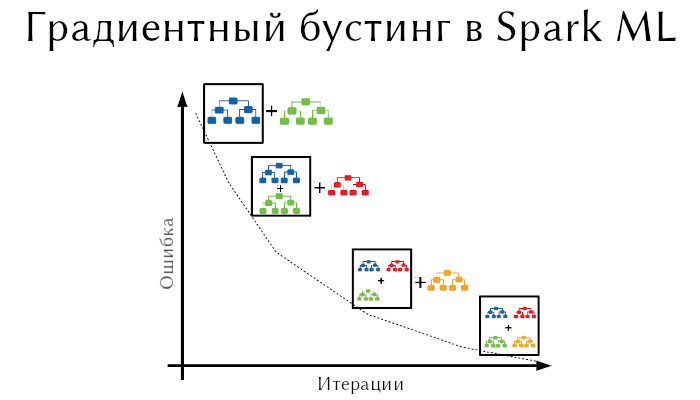
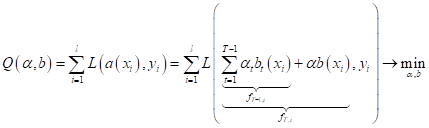Градиентный бустинг python

Градиентный бустинг и стохастический градиентный бустинг
XGBoost [1] — одна из самых популярных и эффективных реализаций алгоритма градиентного бустинга на деревьях на й год. XGBoost изначально стартовал как исследовательский проект Тяньцзи Чена Tianqi Chen как часть сообщества распределенного глубинного машинного обучения. Первоначально он начинался как терминальное приложение, которое можно было настроить с помощью файла конфигурации libsvm. После победы в Higgs Machine Learning Challenge, он стал хорошо известен в соревновательный кругах по машинному обеспечению. Вскоре после этого были созданы пакеты для Python и R, и теперь у него есть пакеты для многих других языков, таких как Julia, Scala, Java и т.










Хотя большинство победителей соревнований на Kaggle используют композицию разных моделей, одна из них заслуживает особого внимания, так как является почти обязательной частью. Речь, конечно, про Градиентный бустинг GBM и его вариации. Возьмем, например.





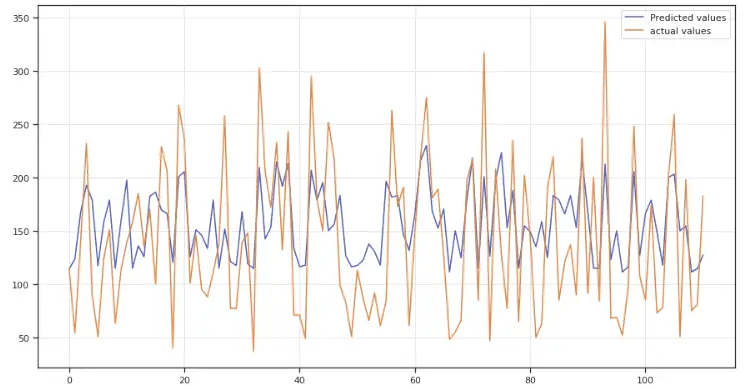

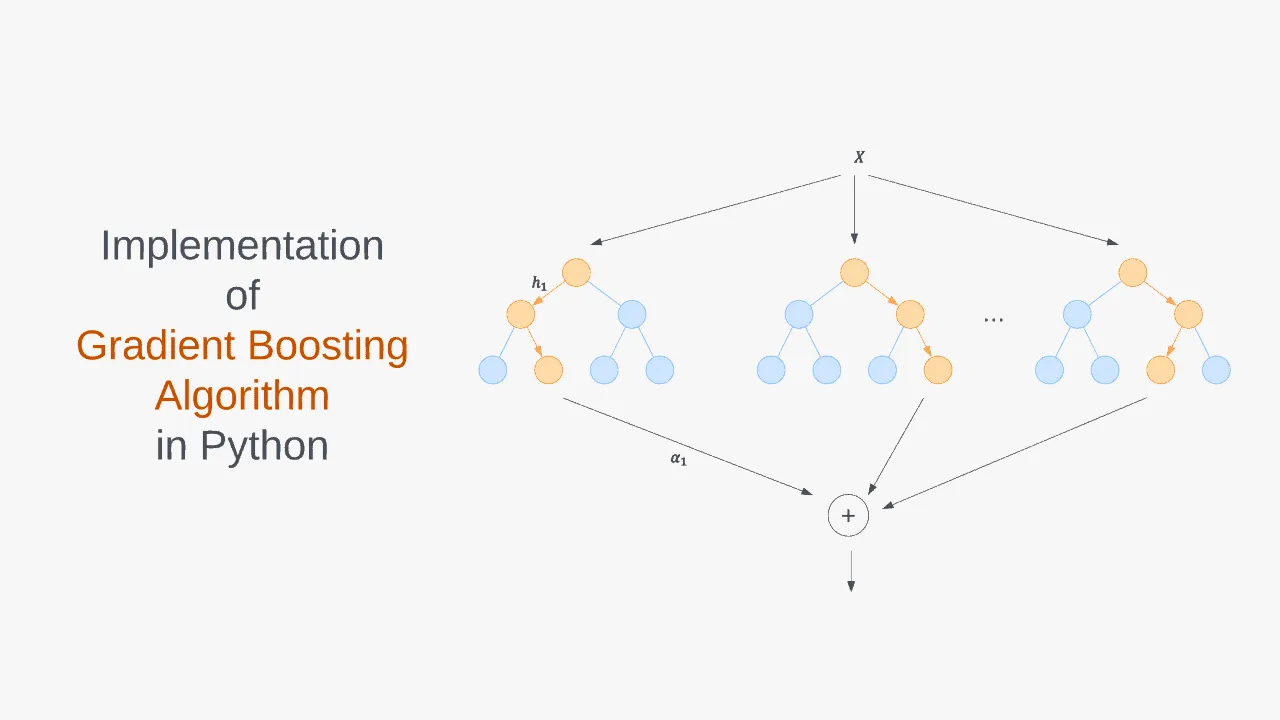


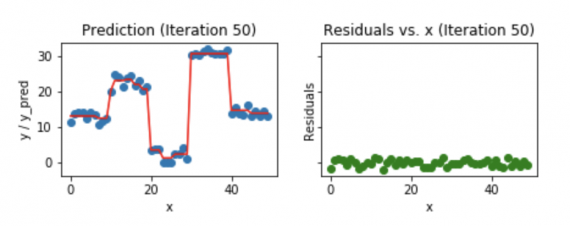
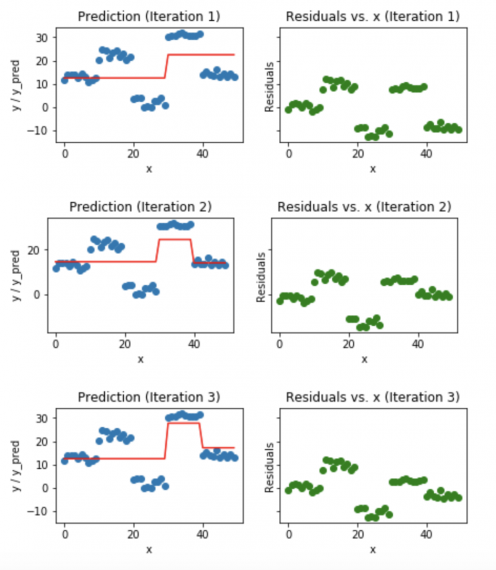
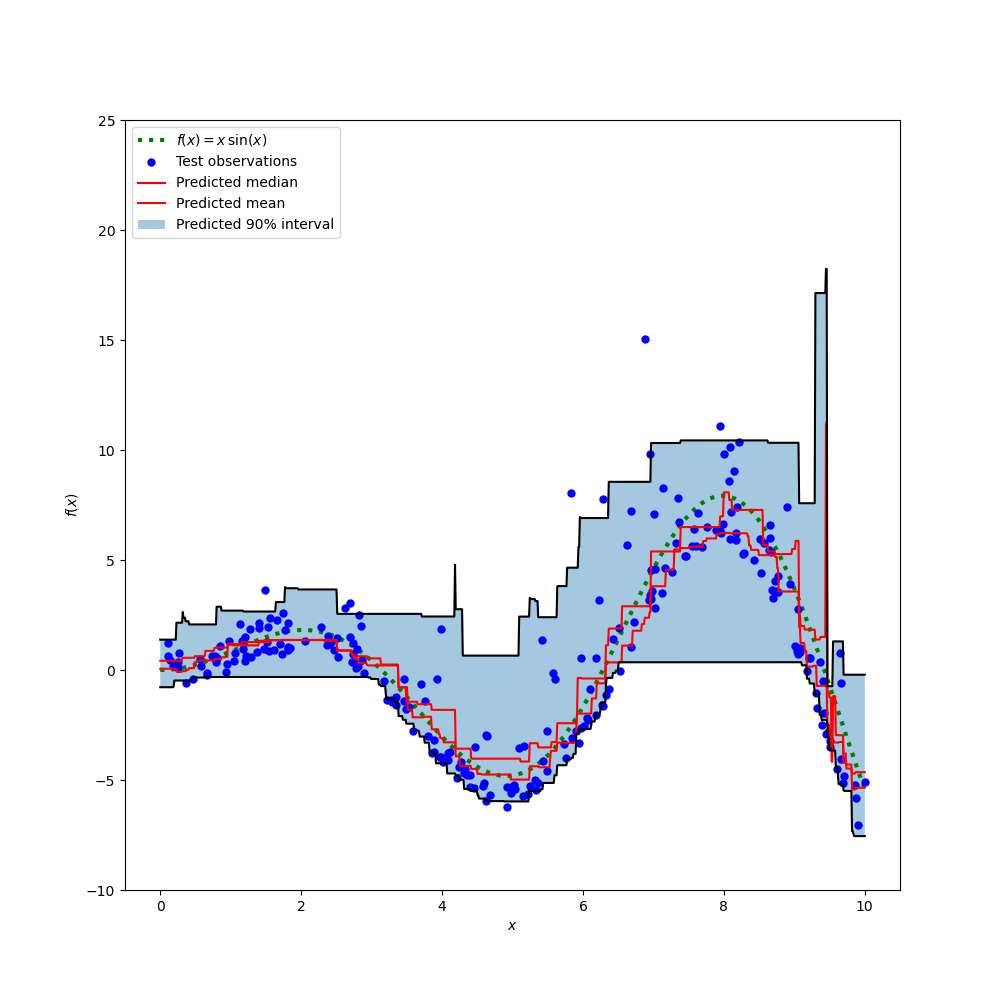
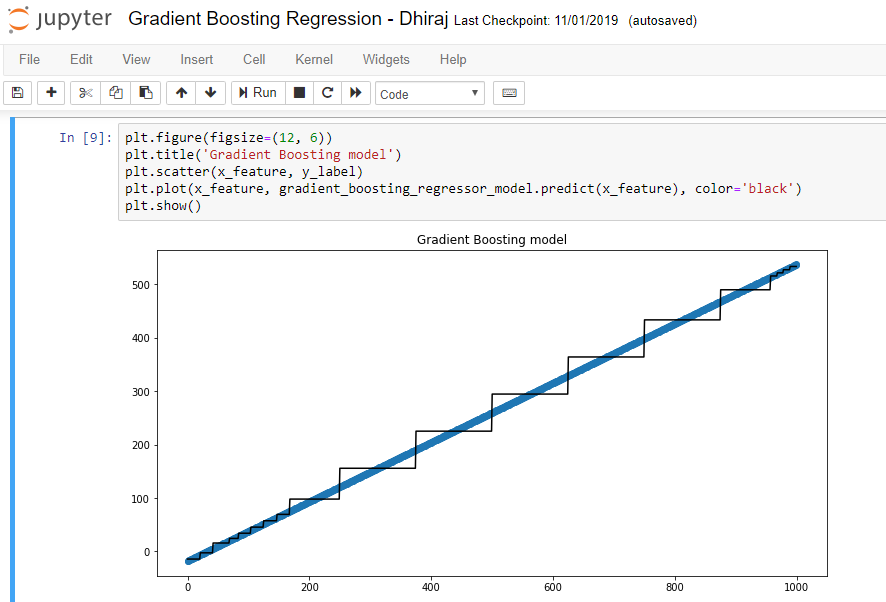
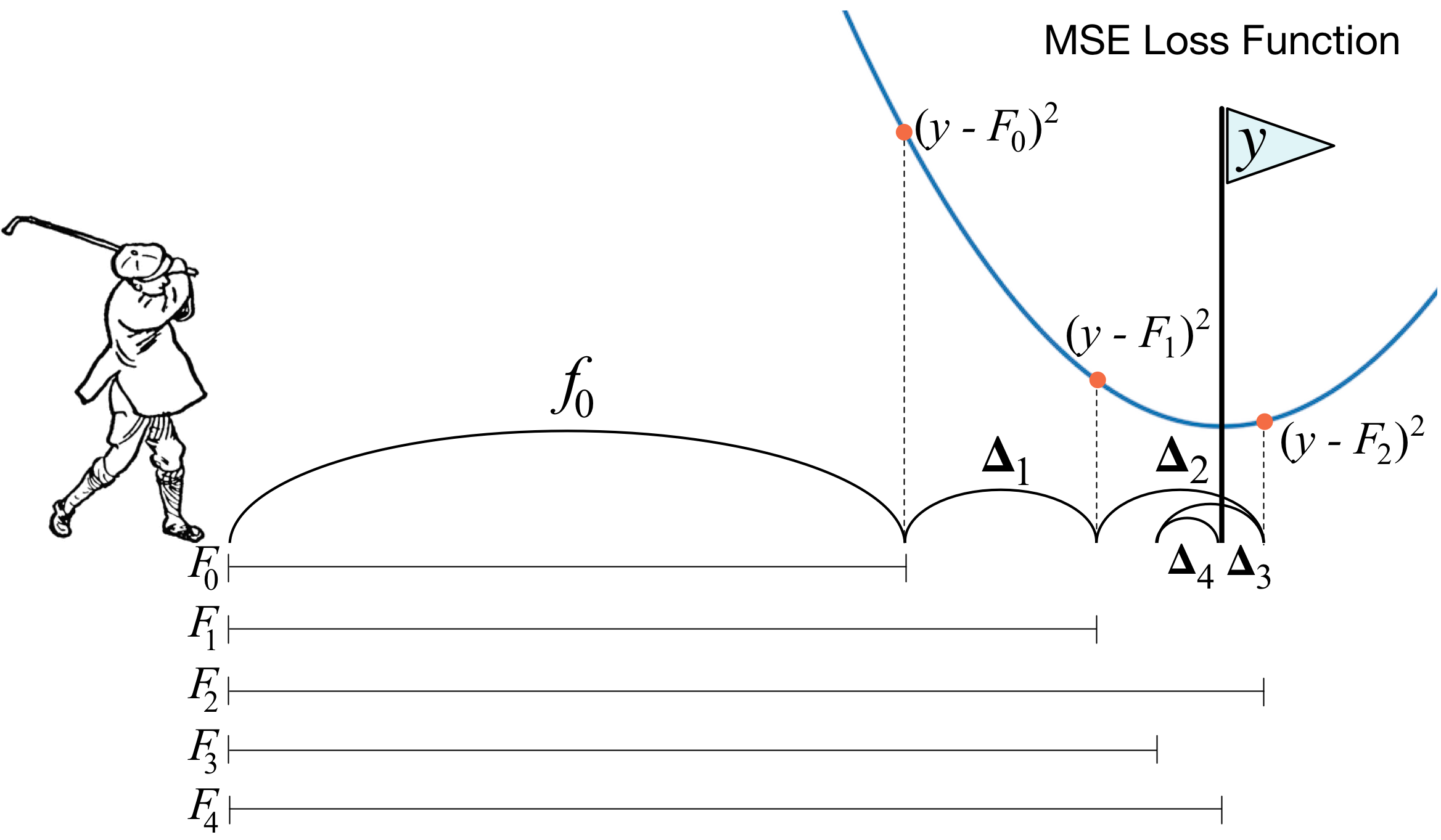
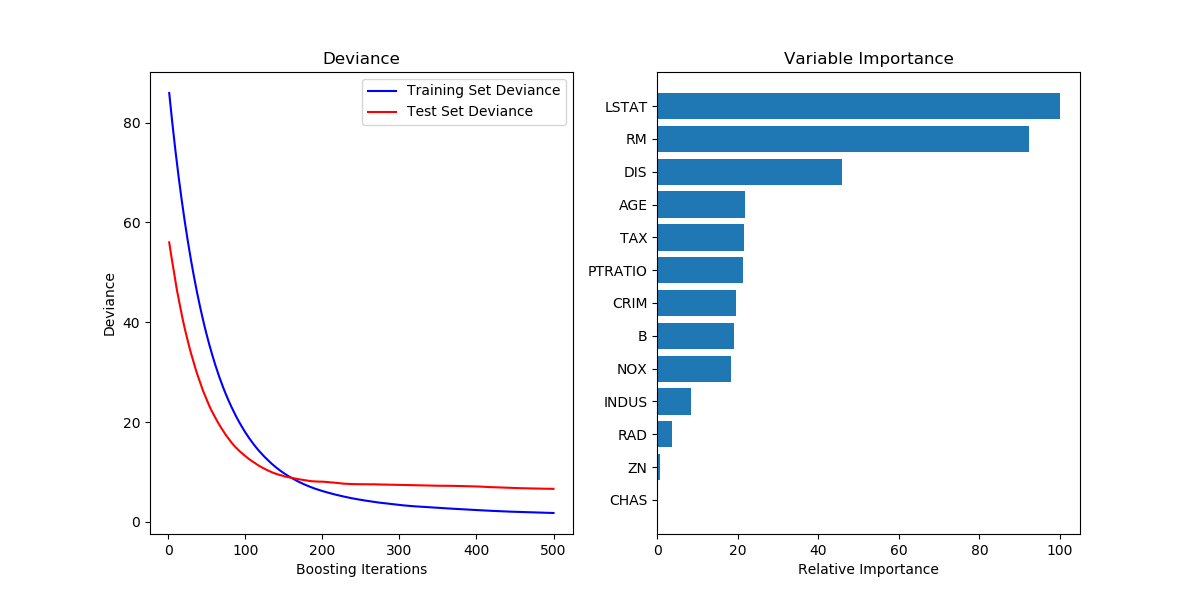
Градиентный бустинг является сильным алгоритмом машинного обучения. Суть метода заключается в построении ансамбля слабых моделей например, деревьев принятия решений , в которых в отличие от бэггинга модели строятся не независимо параллельно , а последовательно. Говоря простым языком, это означает, что следующее дерево учится на ошибках предыдущего, затем этот процесс повторяется, наращивая количество слабых моделей. Таким образом, получается сильная модель, способная к обобщению на разнородных данных. Целью статьи является демонстрация рабочего цикла создания модели на основе машинного обучения, состоящего из нескольких этапов:.